Lost in branches?
First of all, this is not a Git article. This article will give a short introduction to a set of trees almost as powerful as Christmas trees: decision trees.
4 min read
·
By Erlend Faxvaag
·
December 5, 2019

In this article we will briefly go through what a decision tree is, and reasons for why you should be using these trees.
In short, decision trees are models used in the field of machine learning to predict the value of a target variable based on multiple input variables. Some machine learning techniques are hard to learn and near impossible to fully understand - decision trees on the other hand can be really simple.
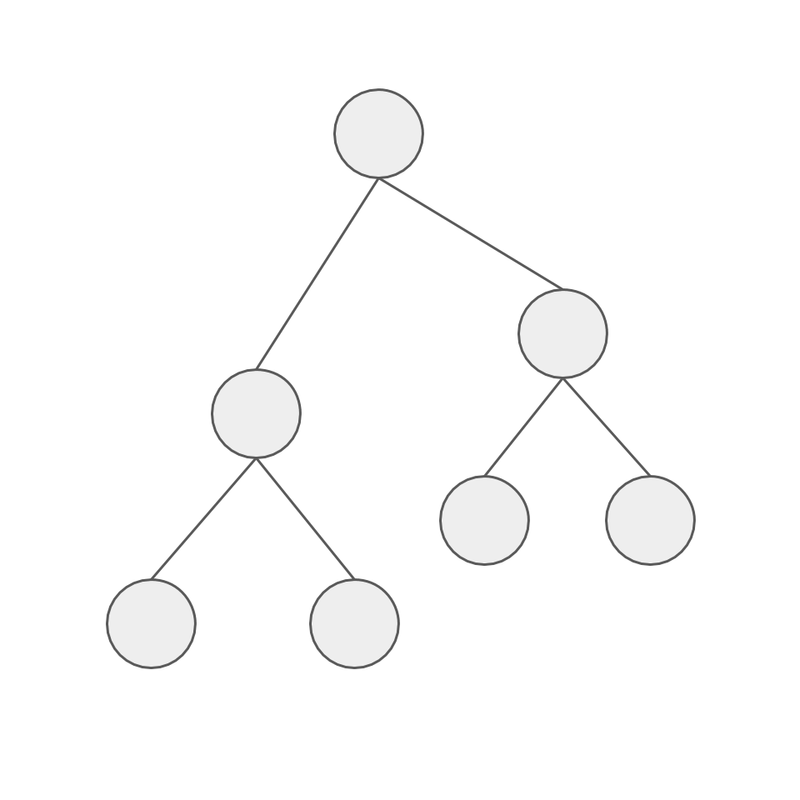
We will start off with a super short description of the structure of a decision tree model. The first gray circle at the top is called the root node, this is where we start. The rest of the gray circles are just called nodes - except the ones at the bottom, without any preceding nodes, these are called leafs. Take a look:
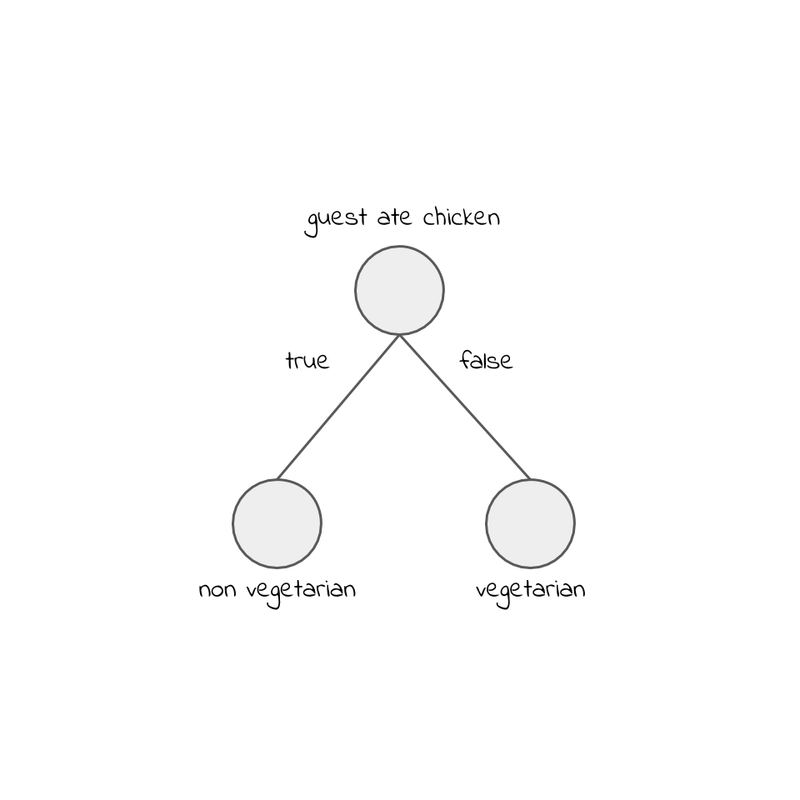
Decision trees can, as already pointed out, be simple and straightforward. Let's make the simplest possible tree, and let's use it for predicting if guests at a restaurant are vegetarian or not. Try it out:
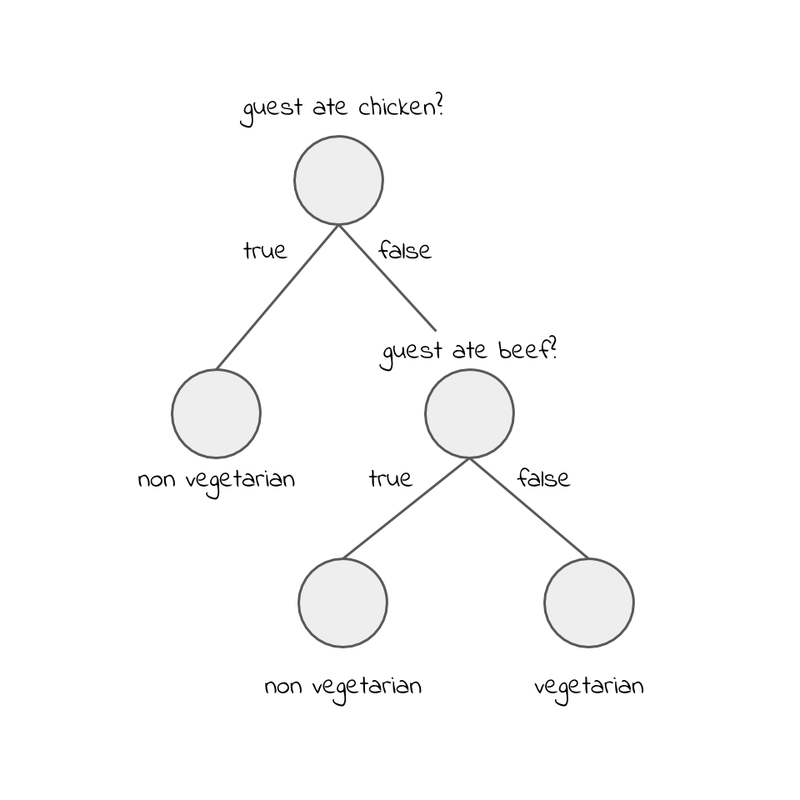
This machine learning technique is pretty intuitive to work with, you start at the top (root node) and work your way down answering questions. The nodes asks the questions, and in the end the leafs gives us the prediction. Let’s add a question:
In the examples above the trees are only made up of one or two questions, and to be fair, there are many different types of decision trees and some of them can be complex and less intuitive to work with. That said, regular decision trees do not need to be a lot more complicated than this. At first one could think trees are too simple to handle complex problems, yet, with more nodes this technique can be surprisingly powerful.
However, trees are not always convenient. With lots of data and features, trees can be huge. They are also prone to overfitting. They get too familiar with training data, and when a real data sample is pushed through the tree, the slightest difference can send you down the wrong track and into a wrong classification. Let’s say you ask the question above at a seafood restaurant. The guests might not be vegetarian, but asking if they ate beef here will get us nowhere.
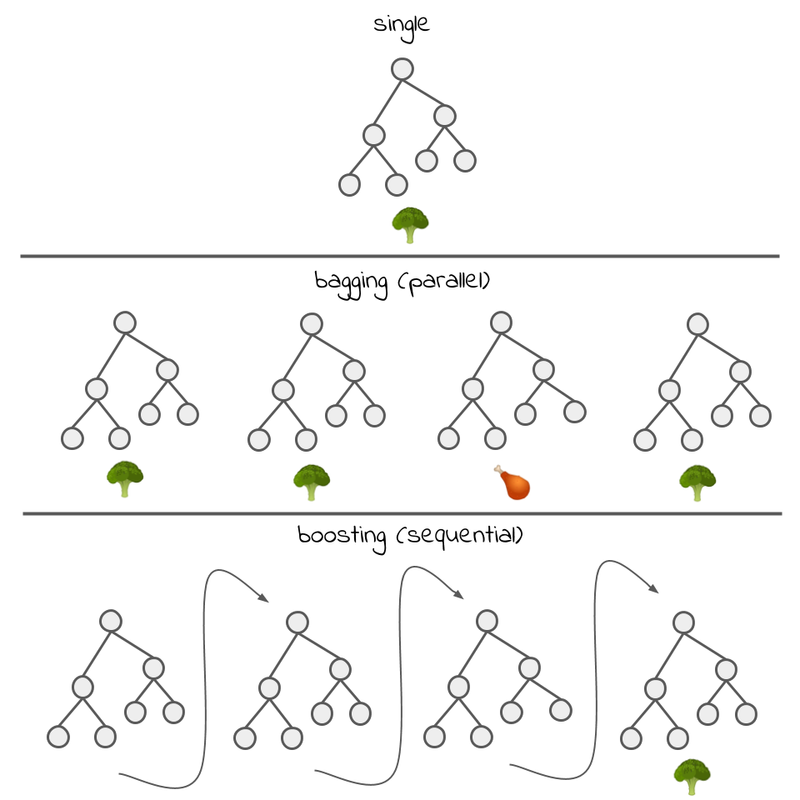
This is where bagging and boosting comes in. These techniques fall in the category: ensemble learning/models. An illustration of bagging and boosting is found below. These are techniques that utilize many weak models to create a stronger one. In other words: ensemble methods combine several decision trees to produce a better prediction than a single tree. Two well known tree based methods that use bagging and boosting respectively are Random Forest and XGBoost. But how can many trees be better than a single tree? Lets focus on bagging. Bagging is simply making a lot of similar models and use all the predictions from these models to give a more accurate result. As we mentioned in the section above, single regular decision trees are prone to overfitting. To fight this we use some simple techniques like: preventing the tree from growing too large, only split on a small random set of features, or train on only portion of the training data. When doing this the trees are less likely to memorize the training data. However, when making hundreds of random trees like this we are more likely to catch edge cases. We ask all our random trees what they think this specific restaurant guest ate, and the class with the most votes wins! All these random trees are called, you guessed it, Random Forest.
Many machine learning techniques are like a black box. For example, in neural networks, we have no idea what conclusions the neural network drew. That's not the case with trees. We can easily visualize the decision, that's just the nature of the trees. By starting at the top and answering questions on our way down, we can see and understand each small decision made up by the tree. It's difficult to get lost, just follow the branch out of the tree. I would say it's easier to get lost in Git branches than in a decision tree.
