Customer segmentation
How can we use methods from machine learning, along with traditional principles from service design, to get a better understanding of our customers and their needs?
4 min read
·
By Jonas Nouri
·
December 8, 2019

As customers and users, we are expecting an ever-increasing level of personalization from the products and services that we use. Providing a personalized offering is a recognition that all customers have different needs but catering to these individually is often too costly and time-consuming to be applicable in practice. We are usually forced to segment our customers into smaller or lager groups with similar needs.
The simplest way to segment customers is to use demographic characteristics as a predictor of the needs for those individual groups. Age and gender are typical examples of such characteristics that are frequently used. Similarly, the number of employees and the sector of operation are often used to segment business customers. This common approach is fine but presents a few problems. Firstly, the demographical characteristics are easy to observe but they are not necessarily perfect predictors of customer needs. And secondly, we are only able to include two, three or perhaps four different characteristics with this approach so we have no guarantee of including the ones that creates distinct and relevant customer segments.
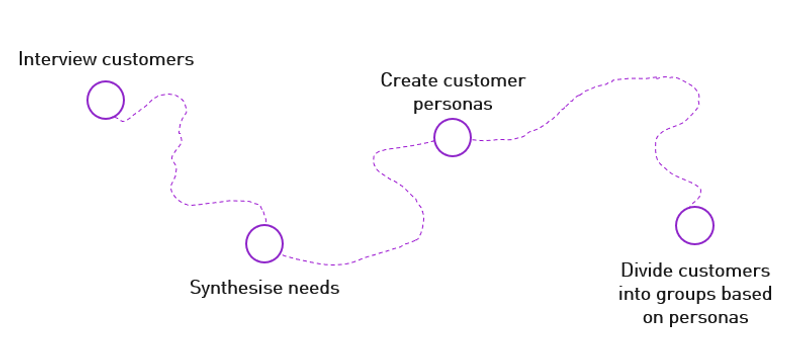
Service design theories recognizes these shortcomings and offers an improved alternative. The common approach to creating customer segments is to identify customer needs through thorough interviewing or observations, studying a wide variety of variables, and creating distinct segments based on these needs. However, interviewing or observing a large number of customers is time consuming and presents a challenge when it comes to finding a representative selection of a perhaps large customer base. How many customers can you interview in depth and fully understand? Ten customers? A hundred customers? Imagine if you could interview them all…
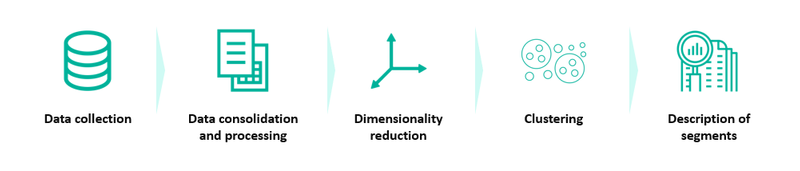
Perhaps data science can provide us with the answer we are looking for? We suggest combining the ideas from service design with quantitative data and machine learning by creating new customer segments through a cluster analysis. This means feeding tons of data to a clustering algorithm and allowing the algorithm to find patterns in the data and combining observations of similar characteristics. Clustering algorithms allows us to examine a large number of customers and variables for each customer, thus avoiding the problem of deciding what data to include in advance. The whole process includes five steps where the first three consists of preparing the data, before we do the actual clustering and finally describe the customers segments.
The key to succeeding with this approach lies, of course, in the data. In order to predict customer needs, we need to look at behavioral and preference data rather than simple demographical data. These sorts of data are available to us today as more and more of our actions leave digital traces, but it often requires qusite a bit of processing and combining data from several different sources. Describing and understanding the segments is also crucial and can require extensive knowledge of the specific field in question.
Succeeding in using a cluster analysis in customer segmentation provides us with a few key benefits:
- Firstly, the approach is objective. We are able to find hard facts about our customer base, their behavior and their preference, meaning there is no need to speculate and make assumptions based on subjective experience. And the best part is that we get to quantify the size of different customer segments we have, thus allowing us to make more informed decisions on for example what segments to target.
- Secondly, the method is robust with respect to choosing the right variables to cluster customer with, because we are able in theory to use all of them! Traditionally we would only be able to use a few variables (sex, age and geography), which has a huge risk of missing out on important aspects.
- And finally, as always with machine learning: If you start with data, you might discover the answer to the questions you did not even think to ask!
Merry Christmas!
