A serverless approach to handle sketchy data imports
Data imports from sources that don't care as much about data integrity and data quality as you do can often be a nightmare. This article describes how we use Azure Functions, ServiceBus, and BlobStorage to mitigate problems that can occur during sketchy data-imports.
2 min read
·
By Asbjørn Bydal
·
December 19, 2019

I currently work for a client where the brand new system we are developing needs to receive a lot of customer data from older systems. Typically data arrives on a daily or weekly schedule in data-formats such as CSV or flat file. Reading and parsing these types of files usually boils down to using the correct library (we use FileHelpers). But cleaning, validating, and synchronizing these imports with existing data can often lead to a good deal of processing per row. Failures or inadequate data will almost certainly occur in one or more rows of incoming files, where the length can be up to ten or even a hundred thousand rows.
To prevent a single error in a row from stopping the entire process, we have adopted a handy pattern using Azure Functions, Blob storage, and ServiceBus queues. We typically receive files during off-hours, and the import process is triggered immediately by using an Azure Function with a BlobStorageTrigger. Instead of letting that single function handle all of the processing, we send one message per data entity into a ServiceBus Queue.
[FunctionName("BlobStorageTrigger")]
public static async Task FileReaderFunction([BlobTrigger("customerimport/{fileName}",
Connection = "AzureWebJobsStorage")] Stream file, string fileName,
[ServiceBus("CustomerImport", Connection = "AzureServiceBusConnection")],
ICollector<string> queue, ILogger log)
{
log.LogInformation($"Recieved new customer file {fileName}");
// Bare minimum processing to separte out all data entites
var rows = BusinessLogic.ReadCustomerCsvFile(file);
// Send all entites to ServiceBus Queue to be picked up and processed
var sendTasks = rows.Select(async t => await t.ContinueWith(async s => queue.Add(await s)));
Task.WaitAll(sendTasks.ToArray());
}The message is picked up by a second Azure Function, which does the heavy data cleaning and validation. By wrapping the heavy business logic in this second function in a try/catch, we can dead-letter any failing data and provide a helpful error description alongside the original message.
[FunctionName("ServiceBusQueueTrigger")]
public static async Task ProcessWishes([ServiceBusTrigger("CustomerImport",
Connection = "AzureServiceBusConnection")] string customerDataRaw,
MessageReceiver messageReceiver,
string lockToken,
ILogger log)
{
Customer customer;
try
{
customer = BusinessLogic.Process(customerDataRaw);
log.LogInformation($"Processed customer {customer.FirstName} {customer.LastName}");
}
catch (Exception e)
{
// A failure to process a data entity will result in a dead-letter message
await messageReceiver.DeadLetterAsync(lockToken, $"Exception occurred during processing of customer: {e.ToString()}");
return;
}
BusinessLogic.PersistToDataModels(customer);
}This approach provides the benefit of being able to discover a bug or validation scenarios that have not been covered, write a fix, redeploy, and replay the failing messages with minimal effort. We use Queue Explorer to check for failing messages and to replay messages when needed.
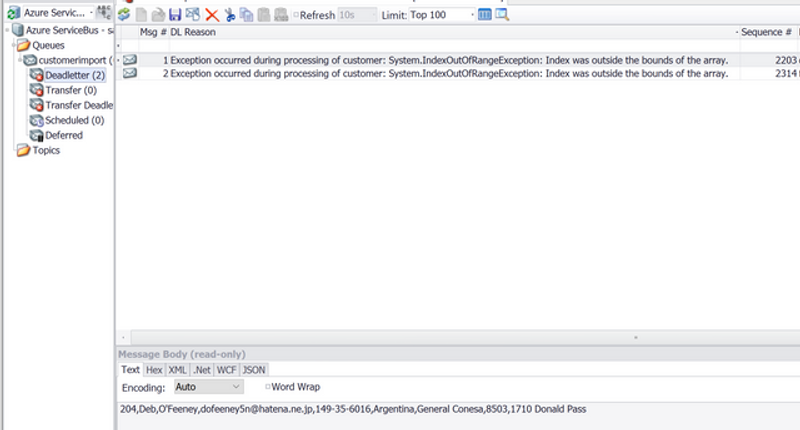
Alongside the dead-lettered message we also provide information on the exception that occurred.
Another benefit of this approach is its ability to scale. A cautionary note here. If you query or send data to other services you don't control during processing, keep in mind that big files with thousands of rows will very fast become thousands of requests. You should make sure that the receiving end is equally capable of scaling or consider throttling your throughput.
Up next...
Loading…
Loading…
Loading…
