What do we say to our robotic overlords? Not today.
There is no doubt that machine learning AIs have impressed us with their superhuman performance in the last few years. Computer programs such as Alphago, Alphazero, and Openai Five have shown that machines can dominate us humans in Go, Chess and Dota2. While these advances in technology are making a lot of people excited, they are also making some people very scared. If machines can beat us mano a mano in some of our most complex games, what is stopping them from dominating us in real life? In an interview with BBC, Stephen Hawkins said that "The development of full artificial intelligence could spell the end of the human race," and during a presentation for MIT Elon Musk called AI our "biggest existential threat." Surely, when Elon Musk and Stephen Hawkins are calling out the dangers of AI, the rest of us should be afraid.
Or should we?
4 min read
·
By Halvor Mundal
·
December 11, 2021

If you are lying awake at night, fearing that your computer is plotting to kill you, then I can assure you that we are nowhere near creating The Terminator just jet. Luckily for us, it turns out that neural networks, the main component of most recent AIs, are extremely easy to trick. With a carefully selected alteration of the input you can fool the AIs into believing anything you want.
Take Google’s Googlenet as an example, a very impressive AI that was able to win the ILSVR2014 competition by correctly classifying 93% of the competition’s 55502 objects from 200 different classes. Many of these classes were difficult to distinguish for non-expert humans such as the Siberian husky and the Eskimo dog that you can see in the image underneath.

You would think that since Googlenet performed well on the images from the competition, which it had never seen before, it should perform well on any image containing the same animals?
Well, no. It doesn’t.
With just a small alteration of an image we can fool the AI into believing it is seeing any of the 199 other classes we want. In the image below, there is a panda to the left which Googlenet managed to classify correctly. This paper shows that with just a small change we can get an image that humans are unable to distinguish from the original, but which completely fools the AI.
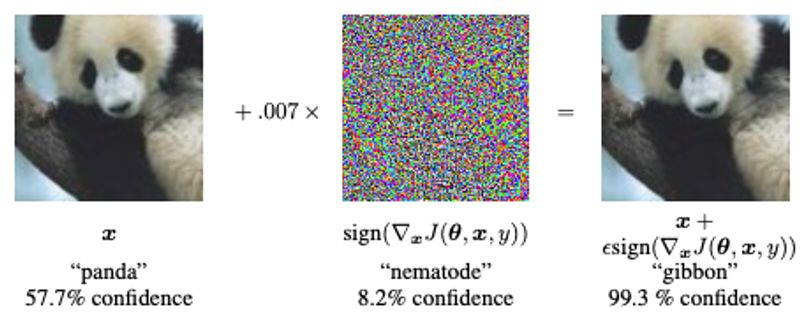
As you can see the AI thought the image to the right contained a gibbon with 99.3 % confidence although there is only 0.7% noise added to it. The rightmost image is what we call an adversarial example, an input that tricks a neural network although it is almost completely identical to something a neural network interprets correctly.
Every AI that uses neural networks is vulnerable to adversarial examples and not only those built for images. We see the same phenomenon in natural language processing, speech to text, translation and all other fields that use neural networks. The adversarial examples are also very easy to create, and if you want to try it out yourself you should try this python repo. All you need is the neural network model and you can create adversarial examples for any neural network. If you don’t have access to the neural network model, that is not a problem. Adversarial examples are transferable between different neural networks, as shown here. This means if you train a neural network on a data set you can create adversarial examples to fool any other neural network trained on the same data set. If that is not possible you can do a decision based attack if you have access to the input and output of the neural network.
You might think that adversarial examples are a weird curiosity that does not exist in the real world, but researchers have shown that even if you print a physical copy of an adversarial image and feed it to a neural network, it is still misclassified. You could also alter physical objects to create adversarial examples. The image below is taken from this paper which describes how you can create adversarial examples in the real world with graffiti or stickers.

In the eight years since adversarial examples were discovered, almost every defence created against them that have been analysed by other researchers have been disproven or shown to be incomplete. Those who are not disproven are only technically correct and do not provide any real defence against adversarial examples. The slide below is taken from a lecture by Dr. Carlini, and it shows what the best defence methods against adversarial examples can do.
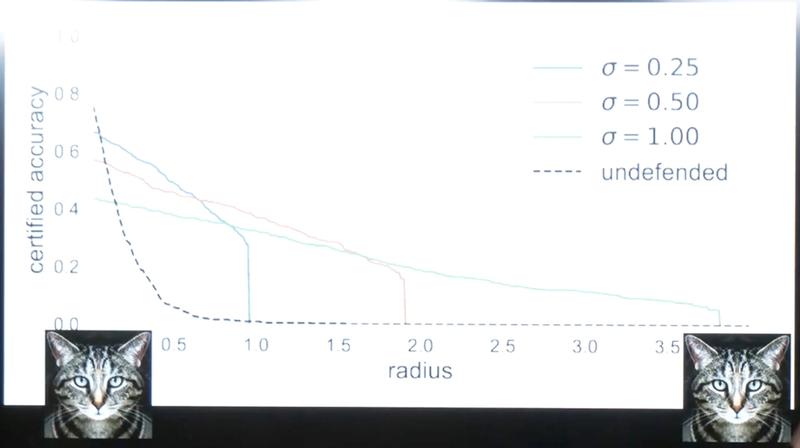
In the slide we see that we can defend against adversarial examples close to the original input, but not against adversarial examples that are just slightly more altered and still indistinguishable to humans. We also see that these defences have a negative impact on the accuracy of the neural network.
To summarize, there is no effective way for a neural network based AI to defend against attacks that are impossible for a human to recognize and fairly easy to create. I think it is safe to say "hasta la vista, baby" to evil Arnold. At least for now.
