What are distributed systems and where can we find them in our everyday life? Bottle CAP and CAP theorem what is the difference?
6 min read
·
By André Perzon
·
December 21, 2021

To answer these questions we need to go back in time to the introduction of network communication between different machines in the '60s and the continued technological advances during the next decades that set the foundation for machine-to-machine communication as we know it today. Machine-to-machine communication provided the ability for machines to coordinate their work towards a common task by communicating. This gave birth to a new kind of system, distributed replication systems, or distributed systems for short, are defined as multiple devices connected via a network cooperating to perform some task. Sabu M. Thampi explains one of the many reasons why distributed systems have grown with the entrance of the information era:
"When a handful of powerful computers are linked together and communicate with each other, the overall computing power available can be amazingly vast. Such a system can have a higher performance share than a single supercomputer."
A problem designers of distributed systems are faced with is the CAP Theorem. CAP stands for Consistency, Availability, and Partitioning. When designing a distributed system you want the system to have strong consistency, always be available, and be operational even when the network is partitioned (you want to reach the center of the illustration in the image below). When a distributed system has geographically long distanced replicas of data and information is sent between the replicas, network partitioning will always be present, may it be due to the human factor or a glitch in the matrix.
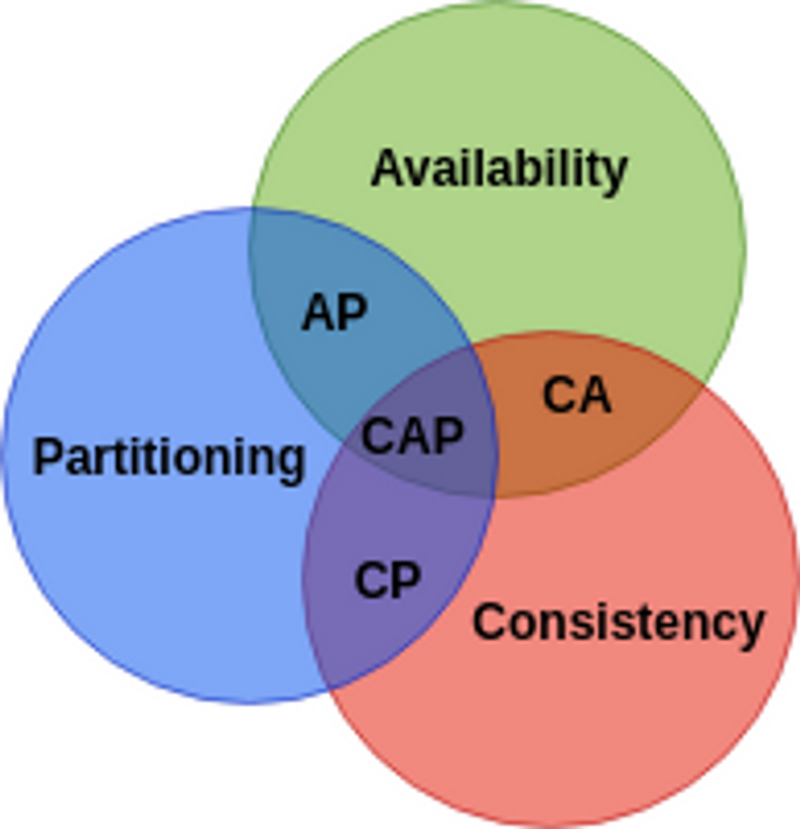
What the CAP theorem states are that you can only have two out of the three CAP properties, thus there are two main options when handling a system that is in a partitioned state (always present). One of the options is to block all operations to replicas thus keeping consistency but providing no availability. The other is to allow all operations to replicas even though it breaks consistency. However, choosing between consistency and availability is not exclusive, trade-offs between consistency and availability can be made, for example, reading but not writing may be allowed or certain data might be changed thus keeping some level of relation between consistency and availability.
Strong consistency is desirable but costly for the system's performance and it also blocks operations thus lowering the availability of the system. A bank transfer requires stronger consistency because of the nature of the transaction than for example Amazon Dynamo
which has sacrificed strong consistency for better availability. Let's face it, in today's society, availability is extremely important. When people can’t access their Facebook or Instagram accounts it is on every newspaper around the globe.
Even though these incidents probably didn't happen because of their servers dropping availability to reach a consistent state, you and I would probably not “accept” their services to be down for a couple of hours every other Tuesday night for them to reach consistency.
The structure of a system can be constructed in two different ways: centralized, where one replica is the primary and the rest of the replicas in the network are secondary, or decentralized where all nodes have the same priority. In a centralized system, all communication from the slave nodes is directed towards the primary node while in the decentralized system communication is made between arbitrary replicas.
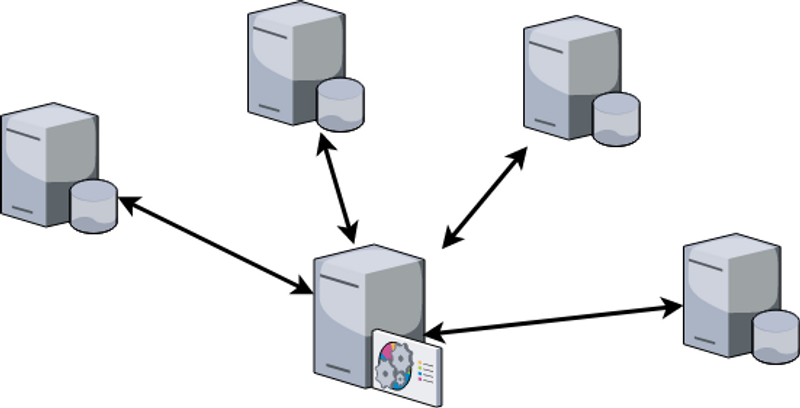
The above image displays a possible network of five replicas where four out of the five replicas are symmetric and the middle replica differs from the other replicas. This is the primary replica and the others are secondary replicas. Secondary replicas that receive updates (e.g. an upvote on a post, illustrated by the 👍 emoji), do not apply the 👍 immediately. Instead, they notify the primary replica that a 👍has been received and wait for the main replica to process consequent updates. An example would be when two secondary replicas receive a 👍 at the same time, notify the primary replica at the same time and apply the two 👍 in the same order due to the decision of order being made by the primary replica.
Now you are thinking why does it matter in which order the 👍 are made, and it doesn't matter for this specific case as in this case two 👍 will increase the total count by two always. But what if the updates were 👍 and 👎 on the same cat picture from the same user? If 👎 is performed before 👍 nothing will happen for the first update as there is no 👍 to remove resulting in one more 👍 on the picture. If the order was reversed, the thumbs would remove each other resulting in no more likes for the cat.
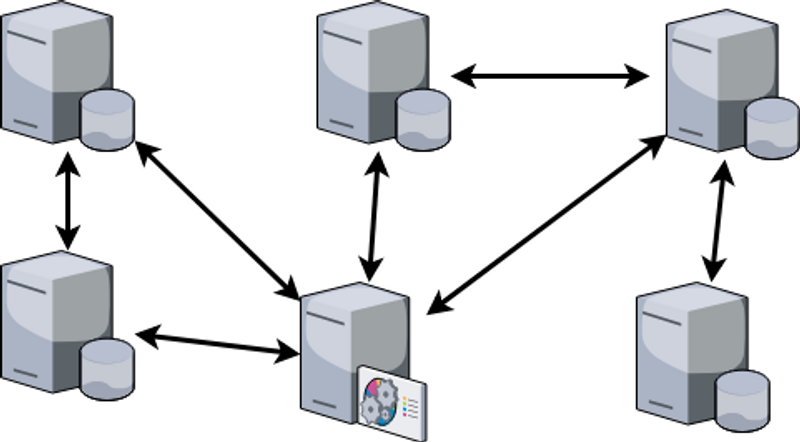
In a decentralized system, all nodes perform actions to reach a consistent state by communicating with other replicas. Actions are performed locally and the changes of the state are communicated to replicas currently in the network. The updates made, propagate across the network and reach all replicas either directly or indirectly if no replica crashes or disconnects indefinitely.
There are pros and cons for a centralized system, where simplicity is a strong argument for this kind of system. A weakness in a centralized system is the single point of failure, all secondary nodes rely on the primary replica for updates. If the primary replica never responds with updates to the secondary replicas they can never update and thus lose both availability and consistency. The system is also faced with the possible bottleneck of the primary replica not having the performance to handle all requests from the secondary replicas, making the whole system not function properly. If this is the case then it does not matter if the secondary replicas might have enough performance to handle their tasks if the primary replica is the point of congestion.
In comparison to centralized replication, decentralized replication has no single point of failure, all replicas can continue working if any replica disconnects. The advantage of no single point of failure leads to higher complexity for keeping consistency when replicating data as all replicas must reach consensus. The complexity of the replication depends on the level of consistency required in the system. Stronger consistency requires more complex solutions than weak consistency.
Both systems have their pros and cons but there is never a universal fit for all use cases. For a larger system like Facebook, a decentralized system may be the best fit and for a DIY project, maybe the less complex central system is the better choice.
Up next...
Loading…
