Hva er Clean Architecture?
Med prinsippene fra Clean Architecture oppnår vi en applikasjon med løse koblinger mellom avhengighetene og økt testbarhet.
5 min read
·
By Espen Ekvang
·
December 23, 2022
Uansett hva vi utvikler er det nødvendig med ulike retningslinjer og prinsipper for at vi skal jobbe sammen og utvikle den stabile, robuste og pålitelige løsningen alle ønsker seg (til jul). Det kan være alt fra hvordan man skriver brukerhistorier, fast tidspunkt for standup, kaffepauser, testbarhet, kodekvalitet og mye mer. Et av disse settene med prinsipper finner vi i Clean Architecture - det er teknikker for å organisere koden din slik at den blir lettere å teste, lettere å utvide og vedlikeholde, med løse koblinger til avhengigheter og grensesnitt.
Dette er på ingen måte noe nytt og man må faktisk over 10 år tilbake for å finne frem da det først ble omtalt av Robert C. Martin (Uncle Bob).
Utfordringen
Mange kjenner til den tradisjonelle 3-lags arkitekturen som består av 1) Grensesnitt, 2) Forretningslogikk og 3) Database, slik som figuren under illustrerer. En svakhet med denne arkitekturen er at det ikke er et tydelig skille mellom kjernen til applikasjonen (domenet og forretningsregler) og "alt annet". Dette kan føre til at man får sterke koblinger mellom ulike deler av applikasjonen og ikke minst mellom avhengigheter inn og ut av applikasjonen som database, eksterne apier og annen infrastruktur.
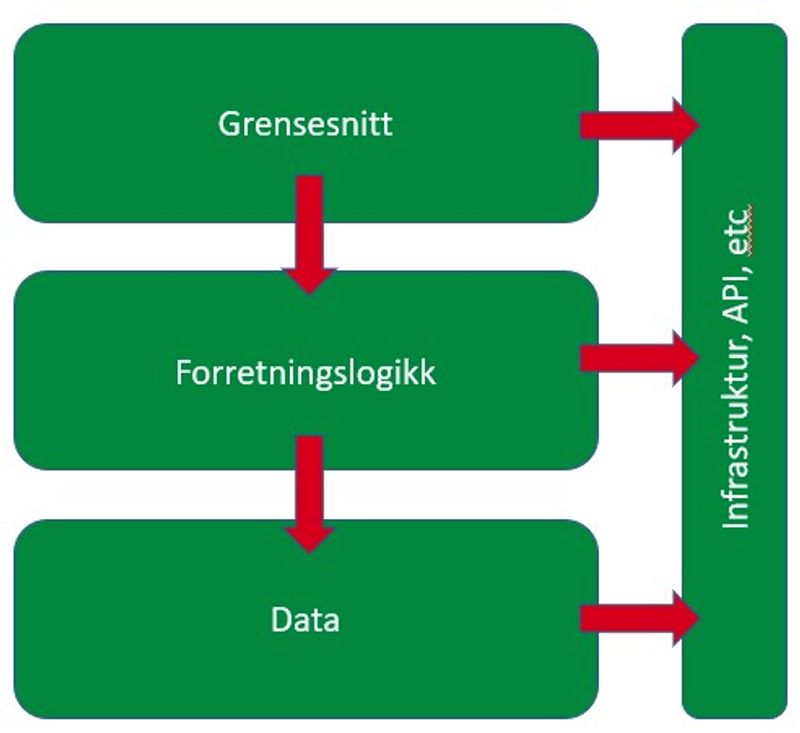
Pilene i tegningen viser at avhengighetene ofte peker "nedover" mot databasen og strukturen på dataene i databasen og ikke minst måten man aksesserer dataene på kan bli gjenspeilet i flere deler av applikasjonen - som er unødvendig og skaper kompleksitet - spesielt med tanke på testbarhet.
Ettersom det ble utviklet løsninger med 3-lags arkitekturen, vokste det frem ønsker om en bedre måter å organisere koden på. Gjennom flere år ble det definert ulike arkitekturer (Hexagonal arkitektur, Onion Architecture, Screaming Architecture m.fl.) der fellesnevneren var å oppnå være løsere kobling mellom eksterne rammeverk, grensesnitt og økt testbarhet.
Løkringer
Tilbake i 2008 ble Onion Architecture definert av Jeffrey Palermo og på samme måte som en løk er satt sammen av ringer, er arkitekturen basert på at hver av de ulike ringene representerer lagene i arkitekturen. Det viktigste her er at avhengighetene peker innover i "løken" på en sånn måte at det som er innerst i løken er tilgjengelig for alle lag utenfor, mens et lag innover aldri kan vite om noe annet enn de lagene som er lenger inn. Det man oppnår er at de innerste lagene (som typisk er domenemodellen) ikke har noen avhengigheter.
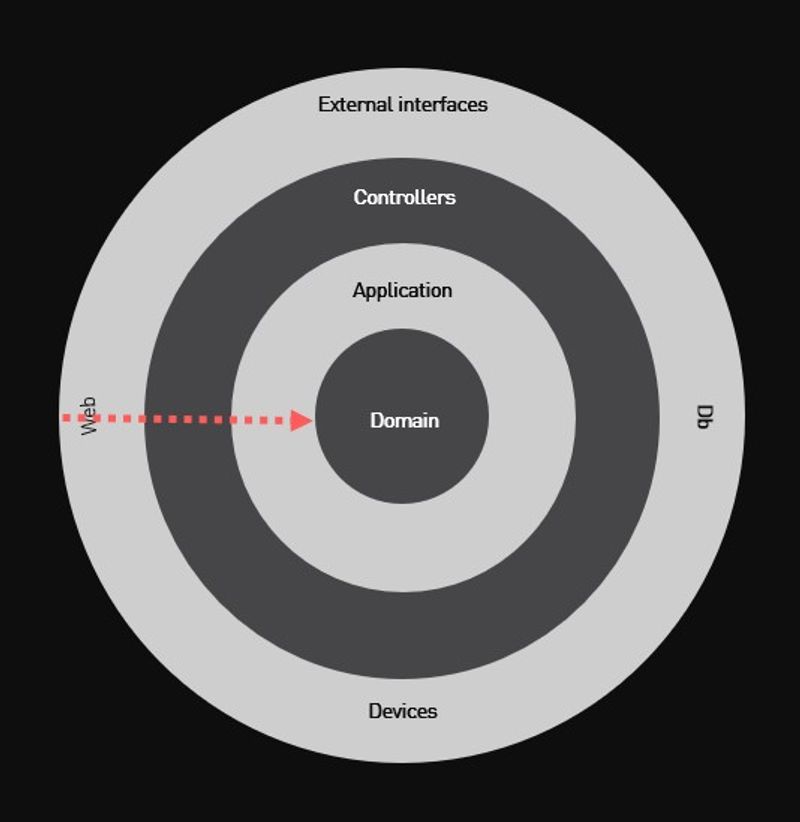
Denne løkmodellen er også den mest brukte modellen for Clean Architecture og ble illustrert av Robert C. Martin slik:
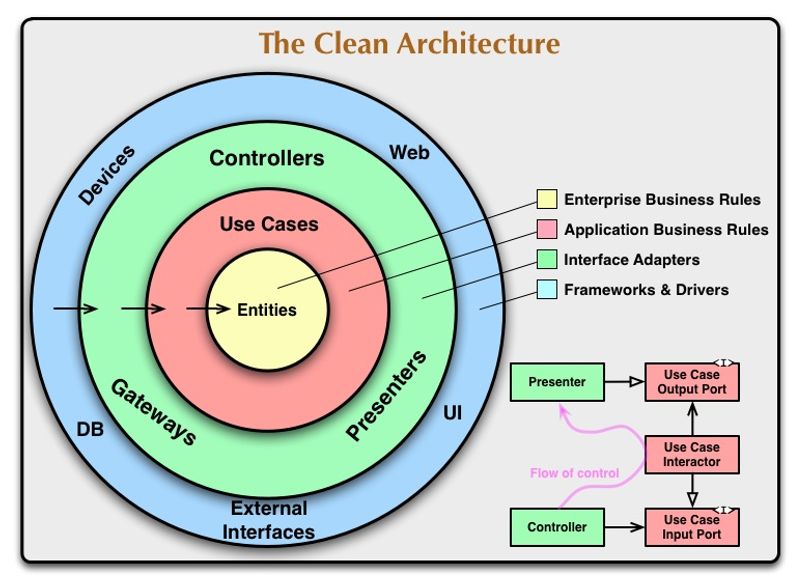
Den største forskjellen fra 3-lags arkitekturen er at alle avhengigheter ligger i ytterste lag av løken. Hovedfokuset blir på logikken og ikke på hvordan dataene lagres (database) eller hvor de kommer fra (api etc). For å ta et konkret eksempel kan man se for seg at man har applikasjonslogikk som ligger i Use Case-laget som skal lagre data. Da vil man i Use Case laget definere et grensesnitt med de metodene man forventer å kunne kalle for å få lagret dataene. Selve implementasjonen av det grensesnittet ligger dermed lenger ut og typisk i det blå laget i figuren til Robert C. Martin.
Vis meg kode!
Det er fint med bokser (løkringer) og piler, men vi trenger å omsette dette til kode. Et par raske søk på internett gir oss flere eksempler på ulike tilnærminger til denne arkitekturen i forskjellige programmeringsspråk. Eksempelet jeg har satt sammen, ligger her, og du kan bruke det som utgangspunkt dersom du ønsker å lære mer om Clean Architecture - det er selvfølgelig ingen fasit - "it depends".
Eksempelet er skrevet i C# og er et veldig enkelt API med funksjonalitet for å:
- legge til en pakke
- hente ut en liste med alle pakker
- hente ut en pakke på en gitt id
Løsningen inneholder fire lag (Web, Infrastructure, Application. Domain) som har avhengighet til hverandre slik som figuren under viser.
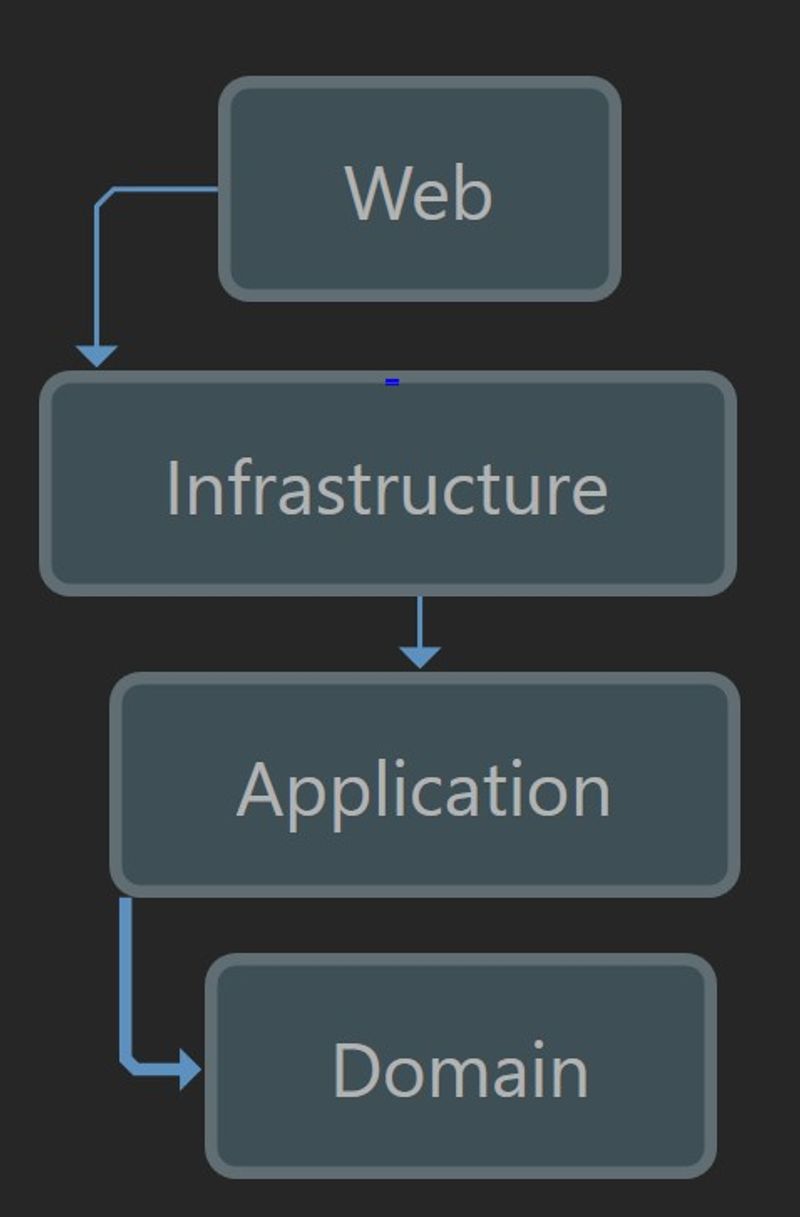
Ansvaret til de fire lagene kan oppsummeres slik:
- Domain
Domeneobjekter; det innerste delen av arkitekturen og skal derfor ikke referere til noe annet lag. - Application
Applikasjonslogikk, query og command handlere; kan bare referere til Domain - Infrastructure
Repsitory; kan referere til Application og Domain. - Web
Controllere, dependency injection setup ++ ; er ytterst og kan dermed kjenne til alle lag.
I applikasjonslaget er det behov for å hente ut og lagre pakker. Applikasjonslaget skal derimot ikke ha noe forhold til hvordan disse pakkene er lagret, det eneste som gjøres i applikasjonslaget er derfor å definere grensesnittet for å få utført disse operasjonene:
public interface IPresentRepository
{
public List<Present> GetAll();
public Present? FindById(int presentId);
public void Save(Present present);
}Hvordan dette implementeres er opptil Infrastructure-laget og dermed kan man starte som i dette eksempelet med en in-memory liste uten at det påvirker applikasjonslogikken. Når man på et senere tidspunkt er klar for å implementere en faktisk database er det bare en ny implementasjon av dette grensesnittet.
Et viktig poeng her er at selve implementasjonen av grensesnittet ligger i et annet lag (Infrastructure) og har private accessor, dermed er det umulig å dra inn den faktiske implementasjonen i applikasjonslaget som sikrer at man kun forholder seg til grensesnittet og ikke blir fristet til å dra inn avhengigheter fra andre, utenforliggende lag i arkitekturen.
Hvor kan jeg lese mer om dette?
Det er som sagt masse ressurser om dette, men jeg vil anbefale at man leser gjennom den originale posten fra Robert C. Martin som finnes her. I tillegg så har Microsoft en artikkel som beskriver flere arkitekturer deriblant Clean Architectures - den finnes her.
God jul!
